Vue 2
这里介绍老版本 vue 相关的知识点
Vue 2 原理相关
Vue 优点
- 轻量级, 只关注视图层,是一个构建数��据的视图集合,大小很小;
- 简单易学:国人开发,中文文档,不存在语言障碍 ,易于理解和学习;
- 双向数据绑定:保留了 angular 的特点,在数据操作方面更为简单;
- 组件化:保留了 react 的优点,实现了 html 的封装和重用,在构建单页面应用方面有着独特的优势;
- 视图,数据,结构分离:使数据的更改更为简单,不需要进行逻辑代码的修改,只需要操作数据就能完成相关操作;
- 虚拟 DOM:dom 操作是非常耗费性能的,不再使用原生的 dom 操作节点,极大解放 dom 操作,但具体操作的还是 dom 不过是换了另一种方式;
- 运行速度更快:相比较于 react 而言,同样是操作虚拟 dom,就性能而言, vue 存在很大的优势。
Vue 2 原理
讲到 vue , 那就必须联想到 MVVM (Model -> View -> ViewModel) MVVM 指的是 Model、View 和 ViewModel,它把每个 HTML 页面都拆分成了这三个部分
- Model 表示当前页面渲染时所依赖的数据源。
- View 表示当前页面所渲染的 DOM 结构。
- ViewModel 表示 vue 的实例,它是 MVVM 的核心。
总之, 更加方便的操作 data 中的数据 基本原理:
- 通过 Object.defineProperty() (vue3.0 使用 proxy)把 data 对象中所有属性添加到 [VM] 上。
- 为每一个添加到 [VM] 上的属性,都指定一个 getter/setter
- 在 getter/setter 内部去操作(读/写)data 中对应的属性
总结一下就是: 当一个 Vue 实例创建时,Vue 会遍历 data 中的属性,用 Object.defineProperty(vue3.0 使用 proxy )将它们转为 getter/setter,并且在内部追踪相关依赖,在属��性被访问和修改时通知变化。 每个组件实例都有相应的 watcher 程序实例,它会在组件渲染的过程中把属性记录为依赖,之后当依赖项的 setter 被调用时,会通知 watcher 重新计算,从而致使它关联的组件得以更新。
响应式
Vue 中最核心的也就是它的响应式,所谓响应式就是采用数据劫持结合发布者-订阅者模式的方式,通过 Object.defineProperty() 来劫持各个属性的 setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
主要步骤:
-
对劫持的数据对象
Observe进行遍历, 包括子属性对象的属性,都加上setter和getter这样的属性,给这个对象的某个值赋值,就会触发 setter,那么就能监听到了其数据的变化 -
Vue 的编译器
Compile解析模板指令, 将模板变量替换成数据, 然后初始化页面, 并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者, 一旦数据有变动, 收到通知, 更新视图。 -
订阅者
Watcher是 Observer 和 Compile 之间通信的桥梁,主要做的事情是: ① 在自身实例化时往属性订阅器(Dep)里面添加自己 ② 自身必须有一个 update()方法 ③ 待属性变动 dep.notice() 通知时,能调用自身的 update() 方法,并触发 Compile 中绑定的回调,则功成身退。Dep 指用于收集 Watcher 订阅者们
-
MVVM 作为数据绑定的入口,整合 Observer、Compile 和 Watcher 三者,通过 Observer 来监听自己的 model 数据变化,通过 Compile 来解析编译模板指令,最终利用 Watcher 搭起 Observer 和 Compile 之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据 model 变更的双向绑定效果。
MVVM 优缺点
优点:
- ⾃动更新 dom: 利⽤双向绑定,数据更新后视图⾃动更新,让开发者从繁琐的⼿动 dom 中解放
- 分离视图(View)和模型(Model),降低代码耦合,提⾼视图或者逻辑的重⽤性: ⽐如视图(View)可以独⽴于 Model 变化和修改,⼀个 ViewModel 可以绑定不同的"View"上,当 View 变化的时候 Model 不可以不变,当 Model 变化的时候 View 也可以不变。你可以把⼀些视图逻辑放在⼀个 ViewModel ⾥⾯,让很多 view 重⽤这段视图逻辑
- 提⾼可测试性: ViewModel 的存在可以帮助开发者更好地编写测试代码
缺点:
- 对于⼤型的图形应⽤程序,视图状态较多,ViewModel 的构建和维护的成本都会⽐较⾼
- ⼀个⼤的模块中 model 也会很⼤,虽然使⽤⽅便了也很容易保证了数据的⼀致性,当时⻓期持有,不释放内存就造成了花费更多的内存
- Bug 很难被调试: 因为使⽤双向绑定的模式,当你看到界⾯异常了,有可能是你 View 的代码有 Bug,也可能是 Model 的代码有问题。数据绑定使得⼀个位置的 Bug 被快速传递到别的位置,要定位原始出问题的地⽅就变得不那么容易了。另外,数据绑定的声明是指令式地写在 View 的模版当中的,这些内容是没办法去打断点 debug 的
数据劫持 Object.defineProperty()
Object.defineProperty() 有三个参数, 分别是:obj, prop, descriptor
obj要定义的对象,prop要定义或修改的属性名称或Symboldescriptor要定义或修改的属性描述符(配置对象)
第三个参数也就是 options, 可以设置的参数有:
- value:给 target[key]设置初始值
- get:调用 target[key]时触发
- set:设置 target[key]时触发
- writable:规定 target[key]是否可被重写,默认 false
- enumerable:规定了 key 是否会出现在 target 的枚举属性中,默认为 false
- configurable:规定了能否改变 options,以及删除 key 属性,默认 false
虚拟 DOM
react和 vue 中都用到了虚拟 dom,所谓虚拟 dom,是一个用于表示真实 DOM 结构和属性的 JavaScript 对象,这个对象用于对比虚拟 DOM 和当前真实 DOM 的差异化,然后进行局部渲染从而实现性能上的优化。
两者在使用 JS 实现模拟真是 Dom 的部分几乎是一致的。在 Diff 部分, 两者的算法也是类似的, 均有 delete, replace, insert, 但是两者的 diff 策略是不一致的;
- Diff 算法借助元素的 Key 判断元素是新增、删除、修改,从而减少不必要的元素重渲染。
- react 中的 diff 策略是, 自顶向下全 diff
- vue 中的 diff 策略是, 跟踪每一个组件的依赖关系,不需要重新渲染整个组件树, 也就是 数据劫持, 然后对每个数据添加 getter/setter, 同时 watcher 实例对象会在组件渲染时,将属性记录为 dep, 当 dep 项中的 setter 被调用时,通知 watch 重新计算,使得关联组件更新。
虚拟 Dom 的数据结构, 主要包括:tag, data, children
- tag:必选。就是标签。也可以是组件,或者函数
- props:非必选。就是这个标签上的属性和方法
- children:非必选。就是这个标签的内容或者子节点,如果是文本节点就是字符串,如果有子节点就是数组。换句话说 如果判断 children 是字符串的话,就表示一定是文本节点,这个节点肯定没有子元素
diff 算法
在新老虚拟 DOM 对比时:
- 首先,对比节点本身,判断是否为同一节点,如果不为相同节点,则删除该节点重新创建节点进行替换
- 如果为相同节点,进行 patchVnode,判断如何对该节点的子节点进行处理,先判断一方有子节点一方没有子节点的情况(如果新的 children 没有子节点,将旧的子节点移除)
- 比较如果都有子节点,则进行 updateChildren,判断如何对这些新老节点的子节点进行操作(diff 核心)。 匹配时,找到相同的子节点,递归比较子节点
在 diff 中,只对同层的子节点进行比较,放弃跨级的节点比较,使得时间复杂从 O(n3)降低值 O(n),也就是说,只有当新旧 children 都为多个子节点时才需要用核心的 Diff 算法进行同层级比较。
vue 2 中使用的是双端 diff,字面意思就是从两端开始分别向中间进行遍历比较的算法
所谓双端 diff,主要有五种比较:
- 新旧头相等
- 新旧尾相等
- 旧头等于新尾
- 旧尾等于新头
- 四者互不相等
其中前四种很好理解,
- 当旧的头和新的头对比 key相同,那么新旧节点的头对应的指针向后移一位,
- 同理 新旧尾相同,那么新旧尾节点指针向前挪一位
- 当旧头和新尾节点key 一样,旧头向后挪一位,新尾节点指针向前挪一位, 这里就会需要节点的移动,将 旧的头节点 重新插入到 当前 旧的尾结点之后
- 同理,旧尾和新头的key 一样,那新头向后挪一位,旧尾向前挪一位, 这里是需要移动的,旧节点数组的末尾索引对应的 vnode 插入到旧节点数组 起始索引对应的 vnode 之前
最复杂的就是四者都不一样时, 至此,双端对比就结束了,这时候,剩下的新旧节点,需要重新生成 key(vnode.key 作为键),
然后,就需要拿着没找到的节点 key 找到旧节点中对应的 key的节点,这时候就意味着,有两种情况: - 旧的列表中有找到, 这是后就需要移动节点,将旧节点中对应的节点插入到 旧头位置之前,然后将旧节点位置中的元素设置为 undefined,
- 旧的列表压根不存在,属于新添加的节点,就直接将 新的 vnode 插入到对应的位置
- 然后就将起始位置后移,直接循环结束 经过上面的比较之后,剩下的
- 新节点剩余,则表示为新增的节点,那直接循环遍历剩余的数据,分别创建节点并插入到就末尾索引 节点之前
- 旧节点剩余,则表示为已经移除的节点,直接从节点数据 中移除
Vue 生命周期
计算属性 computed 和 watch
computed
- 它支持缓存,只有依赖的数据发生了变化,才会重新计算
- 不支持异步,当 Computed 中有异步操作时,无法监听数据的变化
- computed 的值会默认走缓存,计算属性是基于它们的响应式依赖进行缓存的,也就是基于 data 声明过,或者父组件传递过来的 props 中的数据进行计算的。
- 如果一个属性是由其他属性计算而来的,这个属性依赖其他的属性,一般会使用 computed
- 如果 computed 属性的属性值是函数,那么默认使用 get 方法,函数的返回值就是属性的属性值;在 computed 中,属性有一个 get 方法和一个 set 方法,当数据发生变化时,会调用 set 方法。
computed: {
fullName: {
// getter
get: function () {
return this.firstName + ' ' + this.lastName
},
// setter
set: function (newValue) {
var names = newValue.split(' ')
this.firstName = names[0]
this.lastName = names[names.length - 1]
}
}
}
watch
- 它不支持缓存,数据变化时,它就会触发相应的操作
- 支持异步监听
- 监听的函数接收两个参数,第一个参数是最新的值,第二个是变化之前的值
- 当一个属性发生变化时,就需要执行相应的操作
- 监听数据必须是 data 中声明的或者父组件传递过来的 props 中的数据,当发生变化时,会触发其他操作,函数有两个的参数:
- immediate:组件加载立即触发回调函数
- deep:深度监听,发现数据内部的变化,在复杂数据类型中使用,例如数组中的对象发生变化。需要注意的是,deep 无法监听到数组和对象内部的变化。
当想要执行异步或者昂贵的操作以响应不断的变化时,就需要使用 watch。
两者主要使用场景:
- 当需要进行数值计算,并且依赖于其它数据时,应该使用
computed,因为可以利用computed的缓存特性,避免每次获取值时都要重新计算。 - 当需要在数据变化时执行异步或开销较大的操作时,应该使用
watch,使用watch选项允许执行异步操作 ( 访问一个 API ),限制执行该操作的频率,并在得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
总结一下:
computed计算属性 : 依赖其它属性值,并且computed的值有缓存,只有它依赖的属性值发生改变,下一次获取computed的值时才会重新计算computed的值。watch侦听器 : 更多的是观察的作用,无缓存性,类似于某些数据的监听回调,每当监听的数据变化时都会执行回调进行后续操作。
Computed 和 Methods 的区别
可以将同一函数定义为一个 method 或者一个计算属性。对于最终的结果,两种方式是相同的
- computed: 计算属性是基于它们的依赖进行缓存的,只有在它的相关依赖发生改变时才会重新求值;
- method 调用总会执行该函数。
通俗点讲就是, Methods 下就是我们用来定义方法的地方, 在其他地方调用, 总会执行。
下面整理了下生命周期:
先上图:
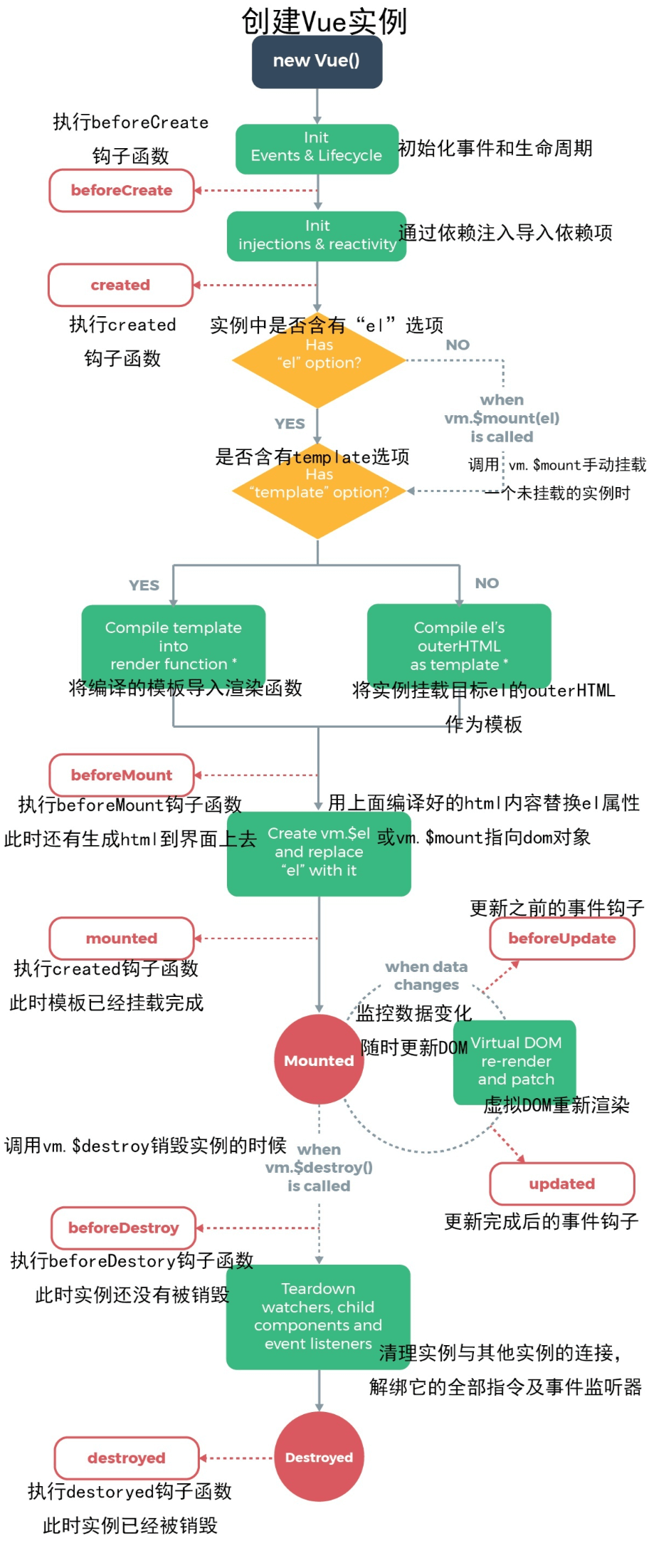
beforeCreate(创建前)
数据观测和初始化事件还未开始,此时 data 的响应式追踪、event/watcher 都还没有被设置,也就是说不能访问到data、computed、watch、methods上的方法和数据。
created(创建后�)
实例创建完成,实例上配置的 options 包括 data、computed、watch、methods 等都配置完成,但是此时渲染得节点还未挂载到 DOM,所以不能访问到 $el 属性。
beforeMount(挂载前)
在挂载开始之前被调用,相关的 render 函数首次被调用。实例已完成以下的配置:编译模板,把 data 里面的数据和模板生成 html。此时还没有挂载 html 到页面上。
mounted(挂载后)
在 el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用。实例已完成以下的配置:用上面编译好的 html 内容替换 el 属性指向的 DOM 对象。完成模板中的 html 渲染到 html 页面中。此过程中进行 ajax 交互。
beforeUpdate(更新前)
响应式数据更新时调用,此时虽然响应式数据更新了,但是对应的真实 DOM 还没有被渲染。
updated(更新后)
在由于数据更改导致的虚拟 DOM 重新渲染和打补丁之后调用。此时 DOM 已经根据响应式数据的变化更新了。调用时,组件 DOM 已经更新,所以可以执行依赖于 DOM 的操作。然而在大多数情况下,应该避免在此期间更改状态,因为这可能会导致更新无限循环。该钩子在服务器端渲染期间不被调用。
beforeDestroy(销毁前)
实例销毁之前调用。这一步,实例仍然完全可用,this 仍能获取到实例。
destroyed(销毁后)
实例销毁后调用,调用后,Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。该钩子在服务端渲染期间不被调用。
随之而来的问题:
created 和 mounted 的区别
- created:在模板渲染成 html 前调用,即通常初始化某些属性值,然后再渲染成视图。
- mounted:在模板渲染成 html 后调用,通常�是初始化页面完成后,再对 html 的 dom 节点进行一些需要的操作。
请求异步数据一般在哪个生命周期中
我们可以在钩子函数 created、beforeMount、mounted 中进行调用,因为在这三个钩子函数中,data 已经创建,可以将服务端端返回的数据进行赋值。
推荐在 created 钩子函数中调用异步请求,因为在 created 钩子函数中调用异步请求有以下优点:
- 能更快获取到服务端数据,减少页面加载时间,用户体验更好;
- SSR 不支持
beforeMount、mounted钩子函数,放在created中有助于一致性。
此外还有三个不常用的生命周期
activated
被 keep-alive 缓存的组件激活时调用。所以改生命周期钩子, 只有 keep-alive 可以使用
注:该钩子在服务器端渲染期间不被调用。
deactivated
被 keep-alive 缓存的组件失活时调用。同上
注:该钩子在服务器端渲染期间不被调用。
errorCapured
在捕获一个来自后代组件的错误时被调用。此钩子会收到三个参数: 错误对象、发生错误的组件实例以及一个包含错误来源信息的字符串。 此钩子可以返回 false 以阻止该错误继续向上传播。
$nextTick
官方解释:在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。
通俗点讲, 就是你放在 $nextTick 当中的操作不会立即执行,而是等数据更新、DOM 更新完成之后再执行,这样我们拿到的肯定就是最新的了。当数据更新了,在 dom 中渲染后,自动执行该函数
原理: Vue 的 nextTick 其本质是对 JavaScript 执行原理 EventLoop 的一种应用。 目前最新的$nextTick 采用的是纯微任务, 在 vue 2.5 版本之后
export default {
name: "HelloWorld",
data() {
return {
testMsg: "原始值",
};
},
methods: {
testClick: function () {
let that = this;
that.testMsg = "修改后的值";
console.log(that.$refs.aa.innerText); //that.$refs.aa获取指定DOM,输出:原始值
that.$nextTick(function () {
console.log(that.$refs.aa.innerText); //输出:修改后的值
});
},
},
};
使用场景:
- created()钩子函数进行的 DOM 操作一定要放在 Vue.nextTick() 的回调函数中, reated()钩子函数执行的时候 DOM 其实并未进行任何渲染,而此时进行 DOM 操作无异于徒劳,所以此处一定要将 DOM 操作的 js 代码放进 Vue.nextTick()的回调函数中。与之对应的就是 mounted 钩子函数,因为该钩子函数执行时所有的 DOM 挂载已完成。
- 当项目中你想在改变 DOM 元素的数据后基于新的 dom 做点什么,对新 DOM 一系列的 js 操作都需要放进 Vue.nextTick()的回调函数中;通俗的理解是:更改数据后当你想立即使用 js 操作新的视图��的时候需要使用它
- 当使用第三方插件时, 希望在 vue 生成的某些 dom 动态发生变化时重新应用该插件,也会用到该方法,这时候就需要在 $nextTick 的回调函数中执行重新应用插件的方法
mixin 混入
官方解释:
混入 (mixin) 提供了一种非常灵活的方式,来分发 Vue 组件中的可复用功能。一个混入对象可以包含任意组件选项。当组件使用混入对象时,所有混入对象的选项将被“混合”进入该组件本身的选项。
是不是很难懂, 那说白话, 就是
将组件的公共逻辑或者配置提取出来,哪个组件需要用到时,直接将提取的这部分混入到组件内部即可。这样既可以减少代码冗余度,也可以让后期维护起来更加容易。可以局部引入,也可全局引入, 例如:图片路径拼接静态服务地址;需要收集用户操作,这种通用的方法或者组件。
这里就会拓展出一个问题, 当我在 mixin 中定义了的属性或方法的名称, 然后在组件中也定义了相同的属性和方法, 这样不会有冲突吗?
- 生命周期同时存在的情况, 会先执行 mixin 中的生命周期, 然后再执行组件中的生命周期
- data 数据共存的情况, 组件中的 data 数据会覆盖 mixin 中 data 的数据
- 方法出现重复的情况, 默认还是会执行组件中的方法,这点和 data 数据类似, mixin 中有组件中没有的方法, 那也是会执行的
直接来个例子
var mixin = {
data: function() {
return {
message: "mixin",
test: "testMixin",
foo: 'abc'
}
}
methods: {
foo: function () {
console.log('foo')
},
conflicting: function () {
console.log('from mixin')
}
}
}
var vm = new Vue({
data: function() {
return {
message: "hello",
test: "test1"
}
},
mixins: [mixin],
created: function () {
console.log(this.$data)
// => { message: "hello", test: "test1", foo: 'abc' }
},
methods: {
bar: function () {
console.log('bar')
},
conflicting: function () {
console.log('from self')
}
}
})
vm.foo() // => "foo"
vm.bar() // => "bar"
vm.conflicting() // => "from self"
这里需要注意的是:提取的是逻辑或配置,而不是 HTML 代码和 CSS 代码。其实大家也可以换一种想法,mixin 就是组件中的组件,Vue 组件化让我们的代码复用性更高,那么组件与组件之间还有重复部分,我们使用 Mixin 在抽离一遍。
优缺点:
- 优:提高代码复用性, 无需传递状态, 维护方便,只需要修改一个地方即可
- 缺:命名冲突, 不好追溯源,排查问题稍显麻烦, 不能轻易的重复代码
总结: mixin 给我们提供了方便的同时也给我们带来了灾难,所以有很多时候不建议滥用它,但是在有些场景下使用它又是非常合适的,这就得根据自己来取舍了。
extend
使用基础 Vue 构造器,创建一个“子类”。参数是一个包含组件选项的对象。
data 选项是特例,需要注意 - 在 Vue.extend() 中它必须是函数
允许声明扩展另一个组件 (可以是一个简单的选项对象或构造函数),而无需使用 Vue.extend。这主要是为了便于扩展单文件组件。
这和 mixins 类似。
这个不多在这里阐述了, 因为用的不多, 可以看下下面这个文章 点击这里
过滤器 filters
Vue.js 允许你自定义过滤器,可被用于一些常见的文本格式化。过滤器可以用在两个地方:双花括号插值和 v-bind 表达式 (后者从 2.1.0+ 开始支持)。过滤器应该被添加在 JavaScript 表达式的尾部,由“管道”符号指示:
<!-- 在双花括号中 -->
{{ message | capitalize }}
<!-- 在 `v-bind` 中 -->
<div v-bind:id="rawId | formatId"></div>
// 组件中过滤器
filters: {
capitalize: function (value) {
if (!value) return ''
value = value.toString()
return value.charAt(0).toUpperCase() + value.slice(1)
}
}
// 全局过滤器
Vue.filter('capitalize', function (value) {
if (!value) return ''
value = value.toString()
return value.charAt(0).toUpperCase() + value.slice(1)
})
new Vue({
// ...
})
// 当全局过滤器和局部过滤器重名时,会采用局部过滤器。
相关问题
Vue 的 template 模版编译原理
vue 中的模板 template 无法被浏览器解析并渲染,因为这不属于浏览器的标准,不是正确的 HTML 语法,所有需要将 template 转化成一个 JavaScript 函数,这样浏览器就可以执行这一个函数并渲染出对应的 HTML 元素,就可以让视图跑起来了,这一个转化的过程,就成为模板编译。 模板编译又分三个阶段,解析 parse,优化 optimize,生成 generate,最终生成可执行函数 render。
- 解析阶段:使用大量的正则表达式对 template 字符串进行解析,将标签、指令、属性等转化为抽象语法树 AST。
- 优化阶段:遍历 AST,找到其中的一些静态节点并进行标记,方便在页面重渲染的时候进行 diff 比较时,直接跳过这一些静态节点,优化 runtime 的性能。
- 生成阶段:将最终的 AST 转化为 render 函数字符串。
template 和 jsx 的有什么分别?
对于 runtime 来说,只需要保证组件存在 render 函数即可,而有了预编译之后,只需要保证构建过程中生成 render 函数就可以。
在 webpack 中,使用 vue-loader 编译.vue 文件,内部依赖的 vue-template-compiler 模块,在 webpack 构建过程中,将template预编译成 render 函数。
与 react 类似,在添加了 jsx 的语法糖解析器 babel-plugin-transform-vue-jsx 之后,就可以直接手写 render函数。
所以,template 和 JSX 的都是 render 的一种表现形式,不同的是:JSX相对于 template 而言,具有更高的灵活性,在复杂的组件中,更具有优势,而 template 虽然显得有些呆滞。但是 template 在代码结构上更符合视图与逻辑分离的习惯,更简单、更直观、更好维护。
scoped 作用与原理
- 作用:组件 css 作用域,避免子组件内部的 css 样式被父组件覆盖
- 默认情况下,如果子组件和父组件 css 选择器权重相同,优先加载父组件 css 样式
- 原理:给元素添加一个自定义属性 v-data-xxxxx, (形如:data-v-2311c06a)来表示他的唯一性。
- 通过属性选择题来提高 css 权重值, 在每句 css 选择器的末尾加一个当前组件的 data 属性选择器的哈希特征值来私有化样式。
如果父组件中想操作子组件中 已经设置 scoped 属性的样式,那么该怎么做呢?
这里就需要用到 /deep/ 叫做 scoped 穿透
<style>
.content /deep/ .button {
color: red;
}
</style>